ʲô��PXImc��
����
�ִ����Ժ�����ϵͳ���ڱ�ø������Ӷ��Ҹ����ܡ��������ľ��ܸ�������ҪӦ���µ���ս����������ٶȵ�Ҫ����ͨ�����ݲɼ������ɵ�Ҫ���Լ��������ݴ�����Ҫ���µIJ��ԡ��������Լ�����ϵͳ�ڱ���Ӧ����ЩҪ���ͬʱ��ʵ�ֵͳɱ�������չ�ԡ���Ӧ�̻������ԣ��Լ�����Եȡ���Щ���ݵĺ������ڣ�����ʦ�DZ���Ӹ������Խϵ͵��ӳ٣�����ʹ������������ݡ�
2009��11����PXIϵͳ���˷�����PXI���м���淶(PXImc)������ͨ��ʹ�õͳɱ����ֳɿ��õļ���Ӧ����ЩҪ����һ�淶������ͨ��һ��PCI Express�����ţ�non-transparent bridge��NTB��������PCI��PCI Express �Ľӿڽ��������߸�������ϵͳ�������ӵ�������Ӳ��Ҫ�� ��PCI Express�����ṩÿ��ǧ��λ����ʵ�������������ͼ�����ӳ٣���ˣ����dz��ʺ���Ӧ����Щ���ݴ����Ӧ������
����Ƥ��̽��������������PXImc�ļ���ϸ�ں;���ʹ�ð�����
���⼼���ײ�
ͼ1��ʾ����һ�����͵Ļ���PCI Express��ϵͳ���˽ṹ��һ����һ�������߽ӿڣ����߸������壬�����ڼ���ϵͳ��PCI�忨����ͨѶ�Ľӿڡ���ϵͳ�У�����ϵͳͨ������������������е�PCI Express��������������Դ��
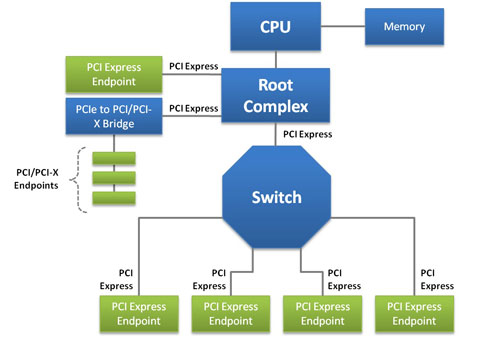
ͼƬ1.PCI Expressϵͳ���˽ṹ
��ǰ���ᵽ�ģ�ͨ����PCI ��PCI Express ��������ͨѶ�㣬PXImc�ṩ��һ���ߴ����͵��ӳٵ�ͨѶģʽ����Ϊ������PCI����֮����������������Ȩ���ն���Դ���������Ķ��־�������������ӵ�и��������ϵͳ��ֱ�Ӿ���PCI����PCI Express�������ӡ�
����һ��NTB��ͨ�����ָ�����PCI��ͬʱ�ṩһ�����ڽ� һ��PCI���ڵ�ijЩPCI ���� ת����һ��PCI���ڵ���Ӧ�����Ļ��ƣ������ڽ����Щ���⡣
ͼƬ2��ʾ��������һ�����ϵͳA��B���������Ǹ��Ե����ڶ�����ȫ������Դ�ķ��䣬ͬʱNTB�Ĵ��ڲ���Ӱ���κ�һ��ϵͳ����Դ�����㷨��
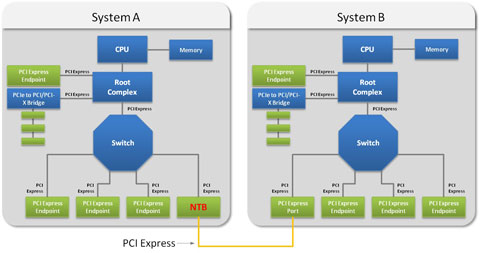
ͼƬ2.ͨ��ʹ��һ��������(NTB)�ģ�����ϵͳ����PCI Express������һ��
NTB�������ڸ����������Դ�������Ӧ������ϵͳ��������PCI�նˡ���ͨ������һ��������������ַ�ռ���ʵ�֡�ϵͳBIOS��ijһ�ض���Χ��������ַ�ռ�����NTB������һ��Դ����ͬʱ������ϵͳA��B��ʱ��NTBȡ������PCI���ڵ���Դ����ͼ3��ʾ��ϵͳA��PCI���ڱ�NTB��õĵ�ַ�ռ䣬����Ϊһ������ϵͳB��PCI���ڵ�������ַ�ռ�Ĵ��ڣ�ϵͳB��PCI���ڱ�ȡ�õĵ�ַ�ռ䣬����Ϊһ������ϵͳA��PCI���ڵ�������ַ�ռ�Ĵ��ڡ�
ϵͳA��B�ڵ���Դ������ɺ�NTB �Դ洢���Ļ���������ϵͳ֮�䴫�����ݡ���Щ���ư����������ڴ������ݵļ�Ĵ����������ж����������Ĵ������Լ�ͨ��NTB�������ĵ�ַ�ռ�ת��Ϊ�෴�ĵ�ַ�ռ䡣
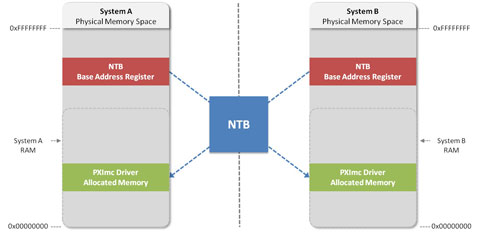
ͼƬ3.ʹ��NTB������PCI����ͨѶ����
NTB��Ȼ�����¼�����������ҵ�ڶ���PCI�ܹ����ͨѶ��Ȼȱ�ٱ��������ڰ�������Ϊһ��ͨѶͨ��֮ǰ��NTB���������Ҫ�Զ����Ӳ����������ơ�
��PXIϵͳ����(PXISA)������PXI ���м���(PXImc)�淶�����˾����Ӳ��������������Ҫ��Ҳ���Ϊʹ��PCI��PCI Express����ϵͳ���ͨѶ�ṩ�˱�����Э�顣��Ӳ���ĽǶ�������ijЩ�����Ѿ��õ��˽�����Ӷ���������������ϵͳͨ��PCI��PCI Expressֱ�ӽ���ͨѶ���������Ĺ۵��������Ѿ�������һ��ͨѶ�ܹ����Ӷ�������һϵͳ�������ø��Ե���Դ��ʵ��������ϵͳ����ͨѶ��
Ԥ�ڵĺ�ʵ�ʲ�õĴ����Լ��ӳ�����
����PXImcʹ��PCI Express��Ϊ����ͨѶ�㣬PXImc��·������ȡ������ʹ�õ�PCI Express�ӿڵ����͡���1�г��˸���PCI Express��·�����۴�����
|
PCI Express ��· |
�� |
���۵ĵ������ٶ� |
���۵�˫�����ٶ� |
|
x4 |
1�� |
1 GB/s |
1 GB/s x2 |
|
x16 |
1�� |
4 GB/s |
4 GB/s x2 |
|
x4 |
2�� |
2 GB/s |
2 GB/s x2 |
|
x16 |
2�� |
8 GB/s |
8 GB/s x2 |
����1.����PCI Express��·�����۴���
ͨ����һ�����͵�PXImc��·�����������ʽ�����ܱȽϣ�NIʹ��ԭ��Ӳ���ͻ���������ջִ����һЩ�����Ļ����ԡ�Ϊ��������Щ�����ԣ������ֱ�����NI PXIe-8133 PXI ExpressǶ��ʽ��������NI PXIe-1082 PXI Express���䣬ͨ��ʹ�û���PCI Express�ĵ�һ��x4ԭ��PXImcӲ������������ʹ����һ���ã�NI���һ��6 µs�ĵ����ӳٺ�670 MB/s������������ǧ����̫����ȣ���Щ�������ִ�Ŵ�����ʮ���Ĵ���������100�����ӳټ�С�����֤ʵ�ˣ��ڽ��������ܶ��������ԺͿ���ϵͳʱ��PXImc��һ������Ľӿڡ�����PCI Express�����ϵĸĽ���PXImc��·�����ܽ��������ߡ�
ʹ��PXImc���������ܶ��������ԺͿ���ϵͳ
�������͵�Ӧ�ý����PXImc������ϴ�1)��ϸ����ܲ��ԺͲ���ϵͳ��2)��Ҫʹ�ö�����CPU��ɷֲ�ʽ������Ӧ�ã��Լ�3)��Ҫ��һ��ϵͳ��ͬʱʹ�û���x86�� CPU��ΪЭ��������Ӧ�á�
��ϸ����ܲ��ԺͲ���ϵͳ
�ɸ�����ɢ����ϵͳ��ɵĸ��Ӳ����Ϳ���ϵͳ������Ӳ���ڻ�����ϵͳ��HIL���ܹ��ṩ��ͬ�Ĺ��ܡ�ͨ������Щ��ϵͳ�ǽ����ڲ�ͬ��Ӳ��ƽ̨�ϣ�ʹ��ϵͳ�Ĺ���������Ӳ��ƽ̨���ܴﵽ�ϼ�ƥ�䡣
PXImc�淶������Щ�����ڲ�ͬӲ��ƽ̨�ϵ���ϵͳ��ͨ��һ���ߴ��������ӳٵ�PCI Express��·����ͨ�š����ʹһ�����ò�ͬ��Ӳ��ƽ̨�Ļ�ϸ����ܲ��ԺͲ���ϵͳ�ﵽ���ܡ�������Լ��ɱ���������ϡ�
ͨ����PXImc��Ϊϵͳ��ͨ�����ߣ���������̫���ͷ����ڴ�������ӿ���ȣ�������ϵͳ�ܹ�ȡ�ø��̵IJ���ʱ����߸����ѭ��ִ�����ʡ����ʹ��Щϵͳ�ܹ������ִ�о����Σ�������ȷ��ģ��ʵ�ʻ�������HILϵͳΪ������
ͼƬ4��ʾ����һ��ϵͳ�ĵ��ͽṹ���������У���PXI ϵͳͨ�����������͵��ӳٵ�PXImc��·��μ�PXIϵͳ������̨ʽ��������ͨѶ���Ӷ�����һ�������ܵĻ�ϲ��ԺͲ���ϵͳ��
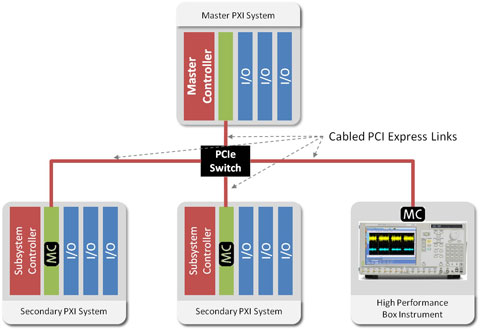
ͼƬ4.һ������PXImc�ĸ����ܻ���Ͳ��ԺͲ���ϵͳ�Ľṹʾ��
ʹ�ö�˴�������ɷֲ�ʽ����
�������ź��鱨(signals intelligence��SIGINT)��ʵʱ�����ܼ���(real-time high-performance computing�� RTHPC)��Ҫ��ʵʱ�����������ݴ�����Ӧ�ã�ͨ����Ҫ�ܼ����ݴ�����������������������ЩӦ�ñ���������ʹ��һ���ṩ�ߴ����͵��ӳٵ�ͨѶ�ӿڣ��ڶ����ɢ�����ڵ����䴦������
����һЩ�ֲ�ʽ����ϵͳ���ֳ��ɱ��������(field-programmable gate arrays �� FPGA)�������źŴ�����(digital signal processors�� DSP)��ʹ���ܹ�Ӧ����ЩҪ���ǣ�ijЩ��Ҫʹ�û�������x86������IP������Ҫʹ�ø��㷽ʽ������㷽ʽִ�м����Ӧ�á�������Щ�����ͨ��PXImc����������ʹ�ý��µĶ��CPU ��PC��Ϊ�ⲿ����ڵ㣬�Ӷ������ֲ�ʽ����ϵͳ��
�ⲻ��ҪӦ���������ἰ������ͬʱ�ṩ��һ��ϵͳ����ʹ��FPGA�Ͷ���DSP��ϵͳ��Ⱦ��и��̵Ŀ����͵���ʱ�䡣
ͼƬ5��ʾ����һ�����е�ʹ��һ��PXI Expressϵͳ��PXImc�ӿڿ���ķֲ�ʽ����ϵͳ�Ľṹ��
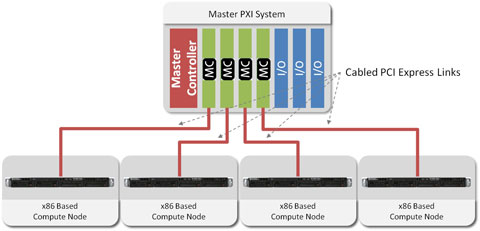
ͼƬ5.����һ��PXI Expressϵͳ��PXImc�ӿڿ��ķֲ�ʽ����ϵͳ��ʾ��
����������У������������������ڸ���I/Oģ������ݣ��������ͨ��PXImc��·�����ݷ��䵽�ĸ�����x86�ļ���ڵ㡣��������Ҫ�Ĵ�������Ҫ��IJ�ͬ������ڵ� ��������ͨ��PC��Ҳ�����Ǹ߶˹���վ��
����Ķ�:
- ...2010/12/24 13:32��ʲô��NI�����Ӿ���
- ...2010/10/20 15:35��ʲô��NI VeriStand
- ...2010/09/09 13:50��ʲô�����ߴ���������(WSN)��
- ...2010/09/09 11:47��ʲô��Xϵ��?
- ...2010/07/20 11:34��ʲô��SC Express
- ...2009/12/14 13:53��ʲô��ϵͳ�ɿ���
- ...��ͼ����������DZ��屳��ij��漶��ȫ���Ҫ��
- ...��ʹ���а�ȫ���ϵ�����洢������ȫ������ϵͳ
- ...������ƫ�ò�����Դ������Ľ��½�չ��Ӧ��
- ...�����¿�˹����ijƷ�����ܲ���������������ƪ
- ...�����ߵ���ʽ�¶ȼ��������ϵͳ�����ŵ���ʧ���Ӱ��(��)
- ...�����ߵ���ʽ�¶ȼ��������ϵͳ�����ŵ���ʧ���Ӱ��
- ...��RTD����ϵͳ�����ŵ���ʧ���Ӱ��
- ...������BR/EDR �� Bluetooth Smart��ʮ����Ҫ����

- ...�� ��о���������Уδ�������˻�������ƴ���������ʽ����
- ...�� ̽�صڶ�������ɽӥ�����¡����������鼼����̳��
- ...�� ��2018�й��뵼����̬����ᡱ�ڽ���ʡ��������
- ...�� �������¹滮��CITE 2019�t���ǻ�δ��
- ...�� ��������������TI���ײ������������ڴ�������ܵ�����
- ...�� �ⷨ�뵼�壨ST����Cinemo��Valens��CES 2018չ��������ʾ������Ϣ���ֽ������
- ...�� �������ɵ�·��ҵ���·�չ�߷���̳�����ھ��ٿ�
- ...�� ������ǿ�Ƴ���PCIM����2017չ
- ...�� GPGPU����������й�оƬ��ҵ�Ŀհش�
- ...�� ��������Ʒ�����Wi-Fi���ӵ��ĸ��ؼ�����
- ...�� �������й�MEMS���ܴ�������ҵ��չ��ἴ���ڰ��������Ļ
- ...�� IAICר��������й�о��Ӧ�ô��£���Ϣ��ȫ�߷���̳��������
- ...�� ���ܿ�����Դǯλ����
- ...�� ���5G���ײ�OTA ���Լ���
- ...�� ����г����������ƶ�Molex��ǿ��������ķ�չ
- ...�� �й���ɫ�������˳�������ٿ��ڼ� ����ѧ���ù�̽��ɫ��չ��ģʽ
- ...�� Efinix® ȫ������AI��Ե���㣬�ɹ��Ƴ�Trion™ T20 FPGA��Ʒ, ͬʱ����Ʒ��չ����ʮ������Ԫ��T200 FPGA
- ...�� Ӣ������������ᣬ�����ǻ�������
- ...�� �����Ʒ�������������ֻᱱ������Դר���ɹ�����
- ...�� Manz���ǿƼ�����뵼������ Ϊ��弶�ȳ��ͷ�װ�ṩ��ѧʪ�Ƴ̡�Ϳ��������Ӧ�õ������豸�������
- ...�� �е���BITRODE������ز���ϵͳ˳��������������Դ
- ...�� �е���FTFϵ�е�ز���ϵͳ�б걱������Դ�����ɷ�����˾
- ...�� �е����ʸ�ѹ��Դ����ʽ����ϵͳ�ɹ������е���è
- ...�� �е������ڵ綯�������ؼ������������ֻ��������Ƚ���������