ͨ����Դ���������������ϣ������������ҵ��������
����Ƕ��ʽ��������˵������ڵ��ĺ�����֮��ȡ��ƽ�⣬��һ�����־õĹ���������Դ�������������������ּ����ĵ���������Ϊ�˰�����Ӧ�̽����Щ��������ս��
ͨ�����ڲ����Եĵ�Դ�����Ͷ�̬Ǩ���������ܺ�
���ݹ�����Դ������IEA�����µı���������������Դ���������Ȳ�����������δ����һ��ʱ���Ի�����������ñ��滹Ԥ������2015�꣬ȫ�����Դ����ÿ�꽫��2.5%���ٶ����������п�����Դ����ռ����������λ�������IJ�����Ҫ�����ڷ�չ�й������ʽ�ĸı䣬�������һ��ҵ������Ϊȫ����Դ���ĵ���������������ס�
ҵ�����ȵĵ�����Ӫ���걨��ʾ������ҵ����Դ���ij������ӣ���������һЩ������Դ���Ĵ������ϡ���Ϊ��Щ��Ӫ�̳��������븴�ӵ���Ϣ��ͨ�ż�����������ΧӲ���豸������������������˶���Դ������Ҳ��֮���ӣ��������¶�����̼�ŷ��������ӣ�ͬʱ�ܺĵijɱ�Ҳ��֮������������Ӫ�̳��ڵIJ���ѹ�����Ʊ�Ҫ���ڽ����ܺ�֧����ͬʱ������ҵ��������������/�������Ӧ�ķ��ɷ��档�������ݴ����Լ��������ʵ���ߣ���Ҫ�����ͨ���豸��֧�֣��ⷴ�����������˵���ҵ�����幦�ġ�
Ϊ�˻�ÿɳ����ķ�չ��������Ӫ�̼��豸�ṩ�̿�ʼ����ʶ������ǿ��Դ����������Ͷ�룬ͨ���ص㿪����ԴЧ�ʼƻ���ʵ�ֽ��ܼ��š�����������ϵͳ�е�AdvancedTCA®��ATCA�����䣬�����������������У��ֶ�����̼�ŷ���Ҫ�����ڻ��䱾����������Ҫ�Լ���ȴɢ�ȵ�����������Ҫ��������Ӫ�Σ��ڴ˽εĶ�����̼�ŷ���ռ������Ʒ�����������ŷ�����80%���ҡ���Ӫ���е�������Σ������豸�������豸������ת����������������ͬʱҲ�ǿ��Թ����IJ��֡�ͨ������ؼ��������գ����ǿ���ʵ���ܺĵĹ�����

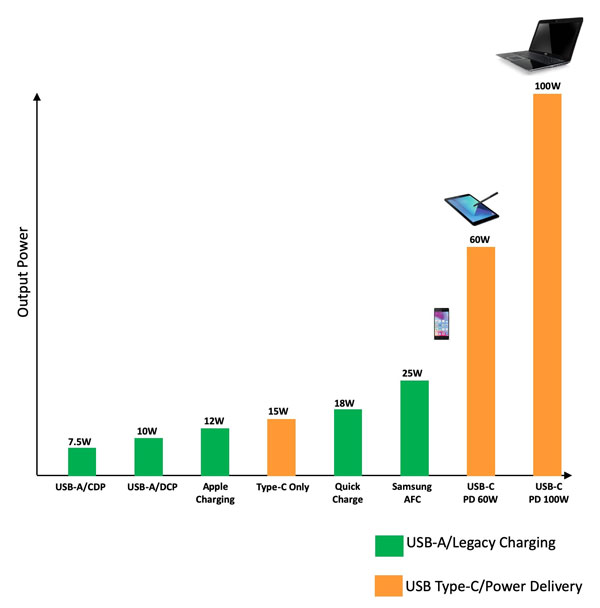
ͼ1. ����36%���������������������豸������������洢�豸�Լ�����װ�ã����дֵ�����ֱ��ת��Ϊ���ܣ���Լֻ��2.4%����������Ч��������Ӧ�����ṩ�Ļ���ATCA�ܹ��������豸��������������ԴЧ�ʵĽ�����������Դ����Լ�����豸����Դת�������е��ܺġ�
��������ƶ���ɢ�ȹ����dz���Ҫ��ͨ������CPU�������ʣ���Դ�����֮���٣��������ͻ����ڵ�ɢ�������ռȽ����˶�����̼���ŷţ��ּ�������ɢ�Ȳ�������Դ���ijɱ���
��Դ����������ͼ���
�����豸�������ԣ�Ҳ��һЩ�����������������������ܺġ����н�Ϊ�����֪�ľ��Ǵ���������̬��Դ������������ʹ���豸��ϵͳ���Ա����óɲ�ͬ�Ĺ���ģʽ���磺����/����/����/������ͨ������������ԶԴ��������ж�̬��ѹ���ںͶ�̬Ƶ�ʵ��ڣ��Ӷ�������Ч�ĵ�Դ������ͨ����̬��ѹ���ںͶ�̬Ƶ�ʵ��ڣ��������ĺ��ĵ�ѹ��ʱ��Ƶ�ʻ������߶����Լ�С�Խ����ܺģ�ͬʱ��������ϵͳ���������衣�������ƹ��ܿ�����ϵͳ������������ܺ�ʹ�÷�ֵ���趨����ֵ��Χ�ڣ�����ֵͨ������ʵ�ʵķ���ģʽ�µIJ��Զ���������CPUʹ���ʵ�ԭʼ���ݡ������Ự�����ȵȡ�
ATCA���伶�ĵ�Դ���������������ڸ������ϵ����⻯��̬Ǩ�ƣ��˲��Կ��Խ����ܺĺ���صijɱ�/���á�����������Ա���Խ�����̬Ǩ�ƽ�һ���������е������豸��VM����Ӧ����������ͬ�������豸��Ǩ�ƣ��Ҳ���Ͽ���ͻ��˵����ӻ�Ӧ�á���̬Ǩ�ƽϵ��͵�һ��Ӧ�þ����Ƽ����е���Դ������������Ӫ��ӵ�еij�ǧ����������豸��VM�������������������ģ�Ϊ�˽�Լ��Դ�ͳɱ������ؾ��⣬��Щ������Ӫ�̿������ö�̬Ǩ�ƶ������豸����ת�ƣ��������ж���������Щ�����豸�еĿͻ�Ӧ�ó���
ʵʱǨ�Ƶ����ò��Կ��Ի����ܺĸ�֪��Ǩ��ģʽ��/���ص��ȵ�ģʽ��������ȡ������ҪĿ���ǽ��ܻ������ʵķ���Ʒ�ʡ�ʵʱǨ�ƽ��ܵĹؼ�����Ч�ضԷ�����д�����ṩ�����ٵ����������������������������ļ�����ζ�ŶԵ�����Դ������ͻ���٣�������������Ҳ��֮���٣��Ӷ�ʵ�ֽ��ܵĽ���Ŀ�ġ�
��Ȼʵʱ�����豸Ǩ�ƾ�������洦������Դ��CPU���ڴ�ȣ��ķ�����ܺĸ�֪�����ϣ����������豸��Ǩ�Ʊ���Ҳ��Ҫ���Ķ����������������һƪ���������豸ʵʱǨ�Ƶ����ܺ�����ģʽ�����£������ڵ�20������ֲܷ�ʽ����������ֻ�������ļ��ϣ���ƪ���½�����һ�����Է�������������ʵʱǨ�ƵĹ��ġ������ʾ�����������ܺĸ�֪�Լ�����������ģ�ͺ�ʵʱǨ�������ĵ�����������١�����ģʽ�����ľ��ߣ����������72.9%��Ǩ�Ƴɱ������ҽ���73.6%��
���úͿ��ƹ�������
�Ե�����ҵΪ�����ֽ��ATCA����ͨ������һ���Ʒ�ʵĵ�Դģ���Լ����ܷ���ϵͳ���������������¶�������ġ�����ʹ��һ�����͵�ATCA����������صIJ��ԣ�ͨ���Զ��������ԣ�������Χ���¶����������ȵ�ת�٣������ȣ����������1/8���Ĺ��Ŀ��Լ���40%��
���ڻ���ʣ���7/8���֣�����ͨ��Ƕ��ʽ��������ÿ����Ƭ�ϵ�CPU���ڴ��Լ������豸��Ƶ�ʺ���ģʽ���Ӷ�ʵ�ֶ�̬��Դ������/������ͨ�����ܹ̼�����������Ŀ��Ʋ����Դ�������ԣ����Դ�������ܺġ�
��ϵͳ�����ĽǶ���������ϵͳ�Ĺ�������������������ˮƽ֮��ʱ���Ϳ����ȶ�����ʵ�ֶ�̬��Դ������ͬʱ�ڷ�ֵ�ڼ�Ҳ����ʹ�ö�̬��Դ�����Լ��ٹ��ġ�Ȼ���������ģ���������Լģʽ����ʱ��������Ƶ�ʽ����ͣ��Ӷ�Ӱ�칤�����ص����ܺ���������
���������ܿ���ͨ����ʾ�����ƶ������ڲ����ⲿ����ʵ�֡��ƶ������������������ĵ�ѹ������������/�ڴ��Ƶ�ʡ��ƶ���Ҳ���ԡ����ơ�����������ͨ��ע����ѭ�����ӳٶ�ָ��Ĵ��������������ﵽʱ�Լ�����������ʱ���������ص����ܿ��ܻ��ܵ�Ӱ�졣
Ƕ��ʽ��Դ��������
��Դ�������������˽ṹ���ɶ��ϵͳ�ػ����̵�������ɣ�����ÿ������������һ����Ƭ����һ���ͻ��������

ͼ2��Ƕ��ʽ��Դ�����Ļ������
�ͻ��˴�����Դ����ϵͳ�Ѽ����Դ�йص����ݡ�ϵͳ�ػ������Ǽ�����ÿһ����Ƭ�ϵ�Ӧ�ã������ߵ�Դ����ģ��Ľ�ɫ�����ṩ��CPU���ڴ桢Ӳ�̡���������⻯�Ĺ��������Լ��������ȹ��ܣ����������������ǰ���¾��������ġ�ʵ�ʵĹ����˿���������̨ʽ�����߱ʼDZ��ϣ�ͨ�����ϲ���ʾ������䡢�忨�ʹ����������¶ȣ���ʵ�ʹ��ĵ���Ϣ��

ͼ3������������ʵ��
������Դ����
ͨ�����Ե����ã���ATCA��Ƭ��CPU�Ĺ���ģʽ�л������ܻ�������Դ����ģʽ��ÿ����Ƭ�Ĺ�����ȳ�������������ģʽ�¼���15%���μ�ͼ4��ͼ5����ÿƬ�忨�ڼ��ط��������¿��Խ�Լ0.4KW�Ĺ��ģ��μ�ͼ5�������һ��14�۵�ATCA������ʹ����10����Ƭ����ÿ���Լ�Ĺ��Ĵ�Լ4KW��


ͼ��������CPU�����ֶ���ģʽ�µĹ��ıȽ�
��̬Ǩ��
���ٹ��ĵ���һ���dz���Ч�ķ�������ֻʹ�ñ�Ҫ���豸����������¼�������Erlang���ʷֲ��㷨��ͼ��6��������Ч����ʹ���ʽϵ͵�ʱ�Ρ�

ͼ6��Erlang���ʷֲ��㷨�ڵ���������������е�ʵ��
ͨ�������ͼ�����ǿ����˽��1����7���ڼ��CPUʹ���ʽϵͣ�Ȼ������ʹ������ʡ��ģʽ�£�ÿƬ�忨��Ȼ�����ĵ��ܡ�����������£�ÿƬ�忨��������Դ�����IJ����»�����90W�Ĺ��ģ���ֵ����ʱ��������140W������İ취��������ʵʱǨ�Ʋ��ԣ��ý��ٵ�CPU��Ƭ�ڴ�����Щ�������أ�ͬʱ������ģʽ�µĵ�Ƭ�л���˯��ģʽ���������������Դ������ģʽ���Խ�Լ����25%�Ĺ��ġ�
ͨ������������������ϵͳ����
�ڹ������غ�I/O�������棬Ŀǰ���г��ͼ�����չ���ƱȽ�������ý���ͳ������ܹ����ϵ�һ��ͨ��ƽ̨��ģ�黯�������������֧�ֶ������豸���ṩ��ͬ�ķ����ܣ���Ӧ�ô��������ƴ��������������źŴ������ܵȡ��������ܹ��Լ��µ������������ߵĹ����������ÿ�����Ա���Ժ����Ľ������������ϵ�ͳһ�ĵ�Ƭ�ܹ��У���Щ���ذ�����Ӧ�á������Լ��������ȡ�ͨ����Ӳ�������ϣ����Դ�����������ܣ���ʹ�õ�Ƭʽ�������ܹ��ڰ�������������е�Ӧ�ô�����ӡ�
Ϊ��˵�������������ϵ��ݱ䣬���������һϵ�еIJ��Է�������Щ���Է������ڵ�һƽ̨�У�ͨ����CPU�������ṩ��DPDK���ϵ�ATCA��������Ƭ�ϣ��Դ���֤��������Ƭ�ṩ�������Լ����ϵ�IPת�����Ƚ���û��ʹ��Intel® DPDK���κ��Ż�ʱ������ԭ�� Linux��Native Linux�� IPת��ʱ�ĵ�����ת�����ܡ�Ȼ�������ٷ�������Intel® DPDK����֮������õ�IPת������������ԭ��
����ƽ�濪����
DPDK��Data Plane Development Kit������ƽ�濪��������һ��רΪx86�ܹ��������ṩ�����������л��������ṩ�˵��ĺ�Run-to-Completion(RTC�����е����)ģʽ���Դ˽ϴ��ȵ��������ݰ��Ĵ������ܡ�����DPDK���������Ż��ĺ�Ч�ĺ����⣬Ϊ�û��ṩ�ḻ��ѡ������������֪�Ļ�������㣨EAL��Environment Abstraction Layer��,��������Ƶͼ���Դ���ṩ�Ż�����ѯģʽ����(PMD��Poll Mode Driver)���Լ�������Ӧ�õ�����API�ӿڣ�ͼ7Ϊ�����㼶�ṹͼ��

ͼ7�� LinuxӦ�û����µ�EAL��GLIBC
�������˽ṹ
Ϊ�˲���ATCA��������Ƭ�ڵ����㴦����ת��IP�����ٶȣ�����ʹ��ͼ8����ʾ�Ļ������в��ԡ�

ͼ8��IPת�����Ի���
���ǵIJ���ʹ����ATCA��������Ƭ��2��10GbE�ⲿ�ӿں�����10GbE Fabric�ӿڣ��ܼ�40G����ͨ���Ƚ�ʹ�ú�δʹ��DPDK�Ľ�������ǿ��Եó����ۣ�����ͬ��Ӳ��ƽ̨�£�ʹ��DPDK���Linux��������CPU�߳̽���IPת�������ܣ���ԭ�� Linux��Native Linux��ʹ��ȫ����CPU�߳̽���IPת����������ȣ�ǰ���Ǻ��ߵ�10����ʹ��DPDK��ƽ̨��3��С���ݰ���ת�����ٿ��Դﵽ>70%��DPDK���Ż�����������ջ����ʵ��10�����ܵ������������һ������IA�ܹ��ĵ�Ƭ�Ŀ��Ʋ�����ݲ��䱸DPDK���Ϳ��Լ���һ��40G��NPU��Ƭ��ͨ��һ��40G��GPU��Ƭ�Ĺ���Ϊ180W�����ͨ�������������Ͽ��Խ�ʡ56%���ܺġ�
��ͼ9���Կ���������DPDK��Ĵ�������Ƭ��IPv4ת�����ܣ������ÿͻ��Ը��õ��Լ۱ȳɱ�����������Ӧ�ôӻ���Ӳ�������紦������ֲ������x86�ļ���ƽ̨��ͬʱʹ��ͬһ��ƽ̨������ͬ�ķ���������������ƴ����Ͱ�����������������ǵIJ��Թ��̺ͽ�������¼�軪�Ƽ���վwww.adlinktech.com��ѯ�軪�Ƽ��ļ�����Ƥ�飺����Intel® DPDK�������軪�Ƽ�aTCA-6200��Ƭʽ����������ʵ�ְ�ת���������ܵ�������

ͼ9������4��10GbE��IPת�����ܱȽ�
����
Ŀǰ�кܶ�;�������Ż���忨/�ദ����ϵͳ�ĵ�Դʹ�ü�Ч�ʡ������Ѿ�������ʹ��Ƕ��ʽ��Դ����������Ƕ��ʽ��Դ�����Ķ�̬Ǩ���Լ��Ż��������Ĺ����������ϵȷ����Ŀ����ԡ�����ÿ��ϵͳ�����úͶԹ������ص���������ͬ�����û��һ�����ԵĽ���취������ÿһ������������Ҫ��ϸѡ���ʺϵļ����Ͳ��ԣ�������Ԥ�ڵ����������ġ�
��δ��������ÿ��ϵͳ�Ĺ����ܶȣ���/����Ӣ�磩�ij������ӣ���Ȼ��ɢ�Ⱥ���Ӫ�Ļ������һ����Ӱ�죬��˵�Դ�������ڵ�����Ӫ�̶��Խ��Ծ���һ����Ҫ���ӵ����⡣
�����軪
�軪�Ƽ����������⡢�Զ����������ͨѶ�Ƽ�֮�Ľ������£��ṩ���������ȫ��������š����ܽ�ͨ����������ͻ���ƾ�Ŷ�רҵ������ִ����ʵ���ͻ���ŵ������Ҫ������ҵ���Ƴ�������Բ�Ʒ����ISO-9001��ISO-14001��ISO-13485��̨�徫Ʒ��TL9000�ȶ�����֤���軪�Ƽ�ΪIntel®����ϵͳ���ˣ�Intel® Intelligent Systems Alliance����Ա��PICMGЭ���PC/104Э��ɲ����ƶ����Ļ�Ա��PXI Systems AllianceЭ�ᶭ�»ἰ�ϸߵȼ���Ա���Լ�AXIe����ս�Ի�Ա��VMEbus����ó��Э�ᣨVITA����Ա��Ŀǰ���������¼��¡��й����ձ����¹������ӹ�˾����ӡ�ȡ��������������а��´���Ϊ���ؿͻ��ṩ��ݷ����ʵʱ֧�֡���ַ��http://www.adlinktech.com/cn��
����Ķ�:
- ...��ͼ����������DZ��屳��ij��漶��ȫ���Ҫ��
- ...��ʹ���а�ȫ���ϵ�����洢������ȫ������ϵͳ
- ...������ƫ�ò�����Դ������Ľ��½�չ��Ӧ��
- ...�����¿�˹����ijƷ�����ܲ���������������ƪ
- ...�����ߵ���ʽ�¶ȼ��������ϵͳ�����ŵ���ʧ���Ӱ��(��)
- ...�����ߵ���ʽ�¶ȼ��������ϵͳ�����ŵ���ʧ���Ӱ��
- ...��RTD����ϵͳ�����ŵ���ʧ���Ӱ��
- ...������BR/EDR �� Bluetooth Smart��ʮ����Ҫ����

- ...�� ��о���������Уδ�������˻�������ƴ���������ʽ����
- ...�� ̽�صڶ�������ɽӥ�����¡����������鼼����̳��
- ...�� ��2018�й��뵼����̬����ᡱ�ڽ���ʡ��������
- ...�� �������¹滮��CITE 2019�t���ǻ�δ��
- ...�� ��������������TI���ײ������������ڴ�������ܵ�����
- ...�� �ⷨ�뵼�壨ST����Cinemo��Valens��CES 2018չ��������ʾ������Ϣ���ֽ������
- ...�� �������ɵ�·��ҵ���·�չ�߷���̳�����ھ��ٿ�
- ...�� ������ǿ�Ƴ���PCIM����2017չ
- ...�� GPGPU����������й�оƬ��ҵ�Ŀհش�
- ...�� ��������Ʒ�����Wi-Fi���ӵ��ĸ��ؼ�����
- ...�� �������й�MEMS���ܴ�������ҵ��չ��ἴ���ڰ��������Ļ
- ...�� IAICר��������й�о��Ӧ�ô��£���Ϣ��ȫ�߷���̳��������
- ...�� ���ܿ�����Դǯλ����
- ...�� ���5G���ײ�OTA ���Լ���
- ...�� ����г����������ƶ�Molex��ǿ��������ķ�չ
- ...�� �й���ɫ�������˳�������ٿ��ڼ� ����ѧ���ù�̽��ɫ��չ��ģʽ
- ...�� Efinix® ȫ������AI��Ե���㣬�ɹ��Ƴ�Trion™ T20 FPGA��Ʒ, ͬʱ����Ʒ��չ����ʮ������Ԫ��T200 FPGA
- ...�� Ӣ������������ᣬ�����ǻ�������
- ...�� �����Ʒ�������������ֻᱱ������Դר���ɹ�����
- ...�� Manz���ǿƼ�����뵼������ Ϊ��弶�ȳ��ͷ�װ�ṩ��ѧʪ�Ƴ̡�Ϳ��������Ӧ�õ������豸�������
- ...�� �е���BITRODE������ز���ϵͳ˳��������������Դ
- ...�� �е���FTFϵ�е�ز���ϵͳ�б걱������Դ�����ɷ�����˾
- ...�� �е����ʸ�ѹ��Դ����ʽ����ϵͳ�ɹ������е���è
- ...�� �е������ڵ綯�������ؼ������������ֻ��������Ƚ���������